현업에서 데이터 처리를 위한 Workflow가 잘 되어있지 않은 상황이다. 외부에서 데이터를 끌어와 변환하고 적재하는 ETL 작업 뿐만 아니라 비즈니스 로직에서 처리해야할 배치가 수십개가 넘어가는데, 이 플로우를 한 눈에 파악하고 수행할 도구가 없다 보니 손이 많이 간다.
개발된 배치의 형태는 다양하다. Spark Job 이 대부분이고 전처리 단계에서는 Shell Script, Python Script, Command Line 등 다양한 형태로 존재한다. 하나의 단위(Task)가 끝나면 다음 단위를 수행하고 마지막으로 처리할 단위를 끝으로 하나의 플로우가 마무리된다.
이들은 각각 Linux상에서 crontab 으로 구현되어 있다. Cron 표현식을 통해 한 단위를 주기적으로 Triggering 하는데, 플로우가 단순하고 배치가 많지 않다면 이 방법도 나쁘진 않다. 하지만 반대라면 여러 Task를 묶어서 하나의 스크립트 파일 또는 Spark Job으로 묶는 꼼수를 쓰지 않는 이상 각 Task별 수행시간을 예측하여 각각 다른 시간대로 cron 작업을 수행하게 해야한다.
우리의 상황은 위에서 언급했듯이 후자이므로 Workflow 도입이 절실하다.
목적
Workflow 도입을 통해 얻고자 하는 바는 명확하다.
- 전체 Flow를 한 눈에 파악 가능
- 배치 파이프라인 모니터링 및 스케줄링
- 각 Task 병렬 처리
- 유연한 DAG 작성
배치 파이프라인을 관리하기 위한 Workflow 엔진들을 리서치하고 각 엔진마다 주요 특징과 장단점을 나열해보았다.
1. Azkaban
Hadoop Job Dependency 문제를 해결하기 위해 LinkedIn 에서 2011년도에 개발한 분산 워크플로우 오픈소스.
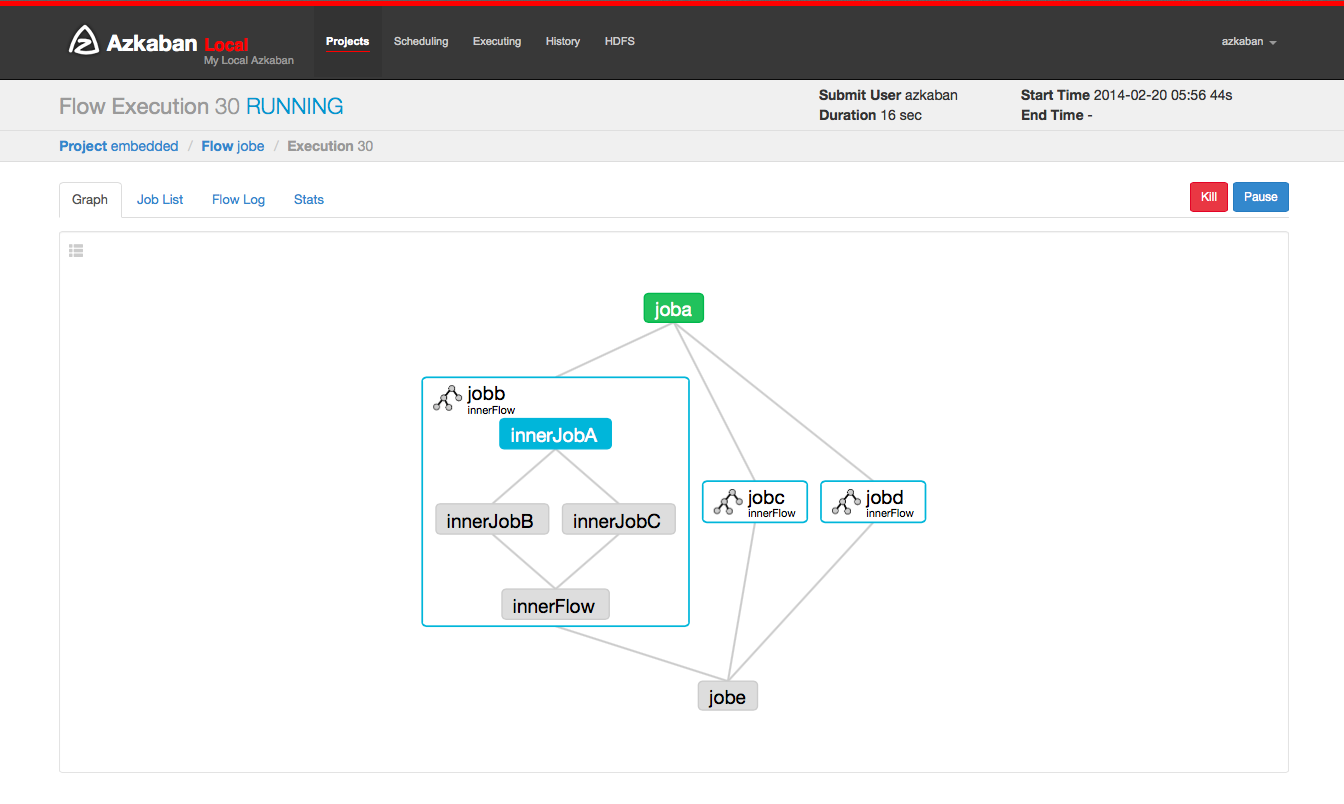
- Hadoop Batch job triggering
- Java로 작성됨
- GUI로 스케줄링 적용 가능 (Custom DSL)
- 구성
- Azkaban Webserver : UI, Auth, scheduling, monitoring
- Azkaban Execution Server
- current 3.0
- solo server
- multiple-executor mode
1.1. 주요 특징
- Hadoop 호환성
- 쉽고 직관적인 Web UI 제공
- Http API 제공 (프로젝트 생성, 수행 등)
- Project Workspace
- 워크플로우 스케줄링
- 모듈화, 플러그인
- 허가, 인증 (authentication, auth)
- User Action 추적
- Multiple Executor
- 성공/실패 Email 알람
- 실패된 Job에 대한 Retry
1.2. 장점
- Hadoop, Pig, Hive 호환성 good
- UI 직관적이고 사용성이 좋음
- 스케줄링과 Rest API 호출 용이
1.3. 단점
- 기본적으로 다양한 기능을 제공하지 않으므로 범용적으로 사용하기 힘듦
- 작업 대기 패턴을 지원하지 않음 (java, script 로 busy waiting 할 수 있으나 리소스 효율정 떨어짐)
- task 병렬 수행하려면 multiple executor mode로 설정해야함
2. Oozie
- Open Source (2009, Apache)
- Java Servlet 기반 워크플로우 엔진
- Hadoop 호환성 (hive, hadoop mr 등)
- 여러 작업을 순차적으로 하나의 논리적 작업 단위로 결합
- command line 수행, Java API, web browser로 스케줄링
- XML로 DAG 구성
2.1. 장점
- Hadoop 진영에서 서포트함
- 성숙된 기술, 문서화가 잘되어있음
- Hadoop 관련 작업을 기본적으로 지원 (Hadoop Job, Pig, Hive, Sqoop)
- 인증 및 허가
2.2. 단점
- XML base (장황하고 복잡함)
- 복잡한 DAG 설정의 한계 (control flow의 제한된 기능)
- UI
- 설치, 설정하기 복잡함
- Zookeeper 클러스터, db, 로드밸런서 등 각각 직접 설정
- 파일럿 적용을 위한 첫 진입으로는 쉽지 않음
3. Airflow
AirBnb 에서 2015년도에 만든 워크플로우 오픈소스. DAG workflow를 정의하여 스케줄링, 모니터링이 용이함.
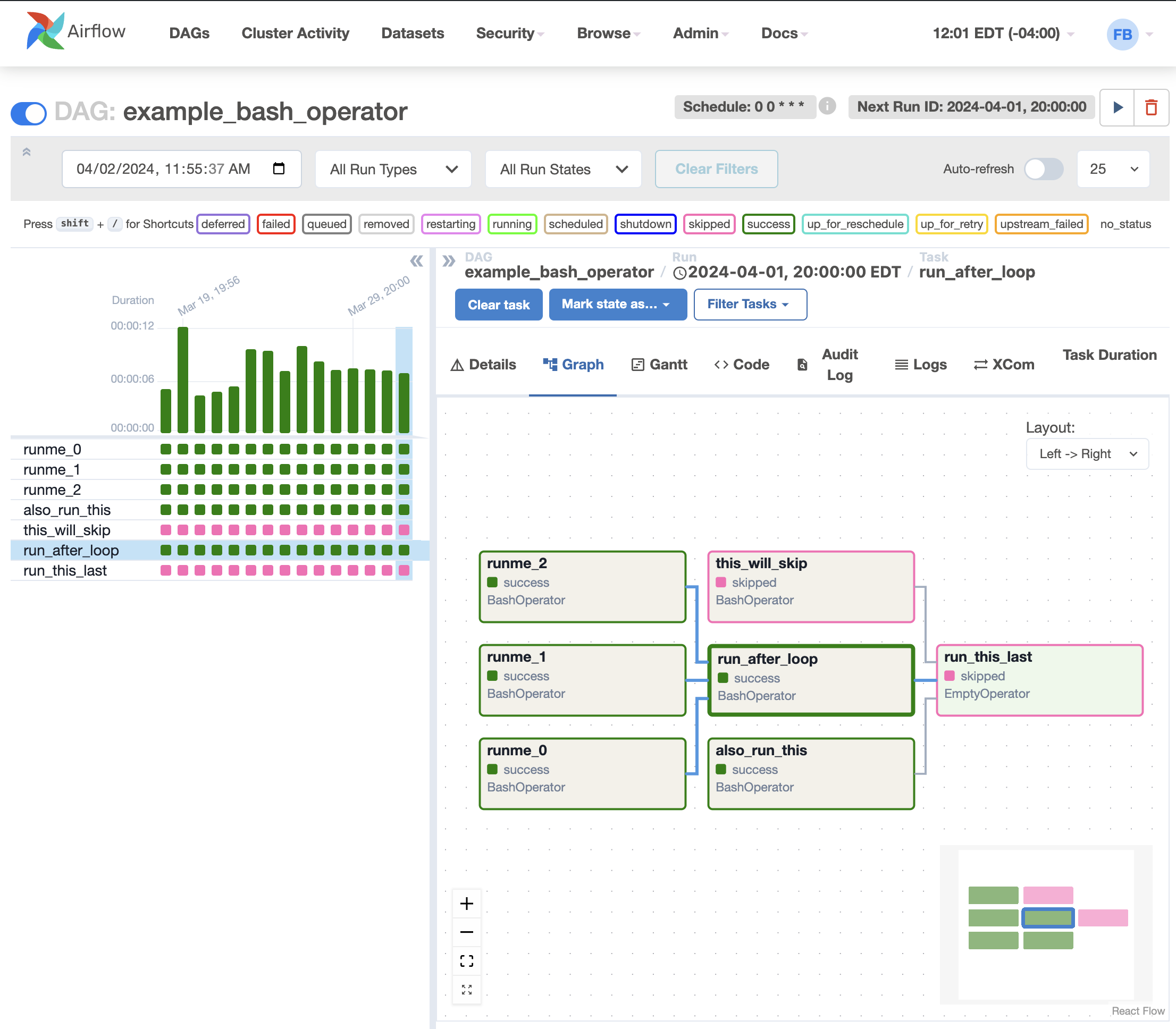
3.1. 주요 특징
- 풍부한 CLI, UI 제공하여 DAG의 depedency, 배치 진행 현황, logs, DAG code 를 한눈에 볼 수 있음
- Python 코드로 다양한 형태의 DAG 구성 (관리, 테스트 용이)
- 모듈성, 높은 확장성 (메시지 큐 사용으로 worker의 수 제약없이 적용)
- Jinja 템플릿 엔진 지원하여 다양하게 파라메터 설정할 수 있음
- 다양한 connector 지원으로 MySQL, MongoDB, HDFS, S3, Hive 등과 상호작용
- Auto retry, Backfill
- Data Profiling (Adhoc Query, Chart)
3.2. 장점
- 거의 모든 종류의 플러그인을 지원하여 범용적으로 워크플로우 사용 가능
- Web UI를 통해 DAG, 배치 현황, 커넥터 등을 관리, 모니터링 가능
- 최근 가장 많이 사용되는 워크플로우 엔진, 활발한 커뮤니티 (사내 도입 사례 및 문서량 가장 많음)
- Python 코드로 정교한 DAG 구성
- 배치 실패 시 retry (특정 배치만 가능)
3.3. 단점
- Oozie 만큼 성숙하진 않음 (발전중)
- task 병렬 수행하려면 추가 설정이 필요함 (RabbitMQ or Redis 설정, MySQL사용)
마무리
이외에도 Luigi, Jenkins Pipeline 등이 있지만 메이저한 3가지를 정리해 보았다. 각각 간략하게 본 것들이라 틀린점이 있고 아직 파악 못한 부분들이 있지만 훑어본 결과 우리 서비스에는 Airflow가 가장 적합해 보인다.
다양한 형태의 DAG도 유연하게 작성할 수 있고 Python으로 구성할 수 있다는 부분이 좋게 보였다. 도입 사례가 많이 보이고 문서화가 잘되어 있는 점, 활발한 커뮤니티, Retry나 backfill 등 다양한 기능들도 한 몫 했다. Multiple Execution 환경을 위해 별도로 MySQL과 Celery 적용을 해야겠지만 일단 적용해보고 ETL 배치들을 하나씩 옮겨보면서 테스트하는 것이 좋아보인다.
Airflow를 중점적으로 공부하면서 설치부터 적용까지 기록해보겠다.
참고
'Data > Big Data' 카테고리의 다른 글
| [Hadoop] HDFS missing block error 해결 (0) | 2023.04.07 |
|---|---|
| [Hadoop] HDFS Balancer 수행 안되는 경우 재수행 하는 방법 (0) | 2023.04.06 |

댓글